Bi-Weekly Advisor Meeting 06 of November 2025
Context
Last meeting, on the 24th of October, we concluded that it would be better to set bi-weekly deadlines to ensure that I didn’t wander off too much in the vast world of RL and Robotics and could ensure progress on my PhD problem. With this in mind, we agreed that it would be good to analyze some review papers on the fields of:
- Contact-Rich Robotics;
- Deep Reinforcement Learning;
- Model-based Reinforcement Learning.
I began my search on Scopus with the following search equation: TITLE ( "Robo*" ) AND ( TITLE ( "contact" ) OR TITLE-ABS-KEY ( "touch" ) ) AND PUBYEAR > 2022 AND PUBYEAR < 2026 AND ( LIMIT-TO ( DOCTYPE , "re" ) )
Which yielded 34 results. Amongst those, a particular one caught my eye, named “A review on reinforcement learning for contact-rich robotic manipulation tasks” (DOI). This paper has 159 citations according to Google Scholar and was published on Robotics and Computer-Integrated Manufacturing (IF:11.4).
PDF Click to expand
In sum, the paper touched on relevant topics such as:
- Rigid vs Deformable Object Manipulation;
- Tasks usually performed for both types of objects;
- Reinforcement Learning Algorithms most commonly used;
Paper Analysis
General Points
Throughout the paper, an emphasis was put on contact stability. Many works dealt with issue due to contact stability.
About 35% of the papers reviewed rely on human demonstration-assisted learning.
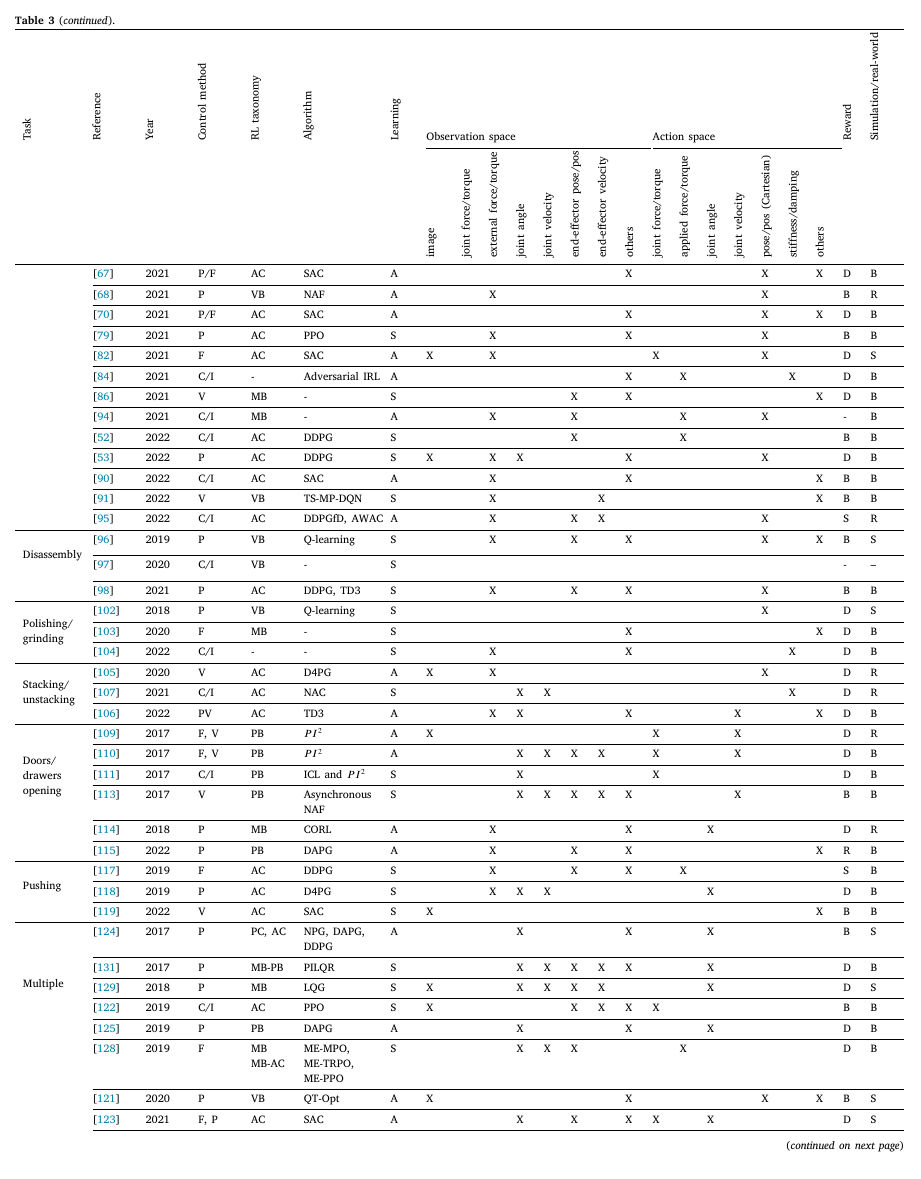
Rigid Object Manipulation
The most common task covered by the papers reviewed was Assembly and Insertion tasks. Peg in Hole tasks are the most common benchmark as the problems that arise with this task are commonly found in assemblies. Performance, sample-efficiency and generalization capabilities are often the 3 desired goals. When it comes to performance, studies measure their performance targeted towards different purposes. Amongst others, precision, stability, safety, execution time or robustness.
Safety wise, authors constrained the robot’s displacement and velocity motion commands, as well as the contact forces on the end-effector. In RL terms, the action space was constrained, which trades safety for prohibiting exploration leading to potentially better policies.
Long training periods was also one of the reported issues. This is a recurrent drawback in high-dimensional tasks where large exploration is required. Therefore, many studies also put their efforts into pursuing greater sample efficiency. Many studies opted to find ways to give initial knowledge to the agents through various methods. For example: Human demonstrations; gathering knowledge from assembly tasks to use in disassembly tasks; combining RL with Fuzzy Logic using more hand-engineered rewards, etc.
On the other end, the pursuit of sample efficiency generally leads to worse generalization capabilities, which in turn also worsens the agent transfer from simulation to reality. In this sense, a widely used approach in multiple studies is domain randomization. This technique allows to uniformly randomize a distribution of real data in predefined ranges in each training episode to obtain more robust policies. Two broad methods of domain randomization may be distinguished: visual randomization and dynamic randomization. Visual randomization targets to provide sufficient simulated variability of visual parameters, such as object location and their estimation in space or illumination. Dynamic randomization can help to acquire a robust control policy by randomizing various physical parameters in the simulator such as object dimensions, friction coefficients, or the damping coefficients of the robot joints, among others.
Other studies in the pursuit of sample efficiency and generalization focus their attention on reward shaping and using models. There are studies using inverse RL from human demonstrations to learn a reward function. More recent studies combined dynamic movement primitives (DMPs) with RL to improve generalization. DMPs allow the contact-rich task to be divided into low-dimensional, easily adaptable sub-tasks, which also increase training efficiency. Others for instance, used meta-RL. Meta-learning enhances sample efficiency, as it enables explicit learning of a latent structure over a family of tasks that can later be easily adapted to the target task.
In addition to assembly tasks, these tasks and associated challenges are also explored in studies:
- Disassembly;
- High variability between items;
- Polishing and Grinding;
- Contact-stability is imperative;
- Stacking and Unstacking;
- Different from Pick & Place because there is object to object contact;
- Door/Drawer Opening;
- Finding the correct axis of movement;
- Pushing;
- Unknown surface friction properties;
- Mixing/Scooping;
- Multiple tasks
- High need for generalization.
Deformable Object Manipulation
Many of the problems presented before still hold here. For the moment I don’t plan on working with deformable objects so I will not elaborate further here. Nonetheless. there are the most frequent tasks:
- Rope Folding;
- Fabrics Folding;
- Tissue tensioning;
- Tissue cutting;
- Peg in hole (with one of parts being deformable).
Here lies a distribution of tasks covered by studies for both Rigid and Deformable objects:
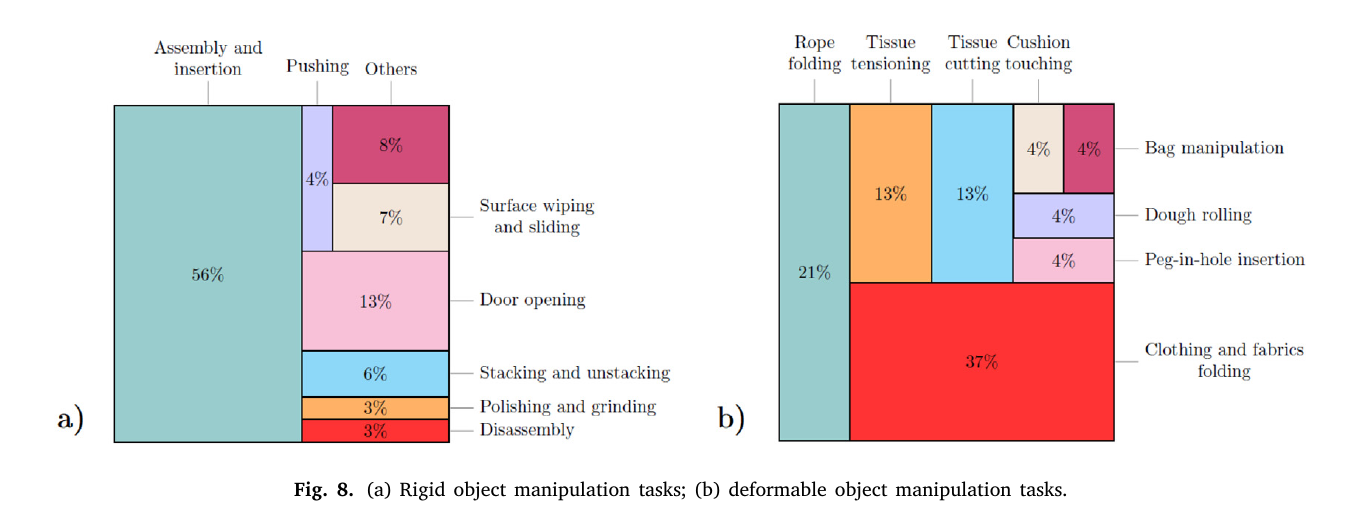
Comparison of algorithms used
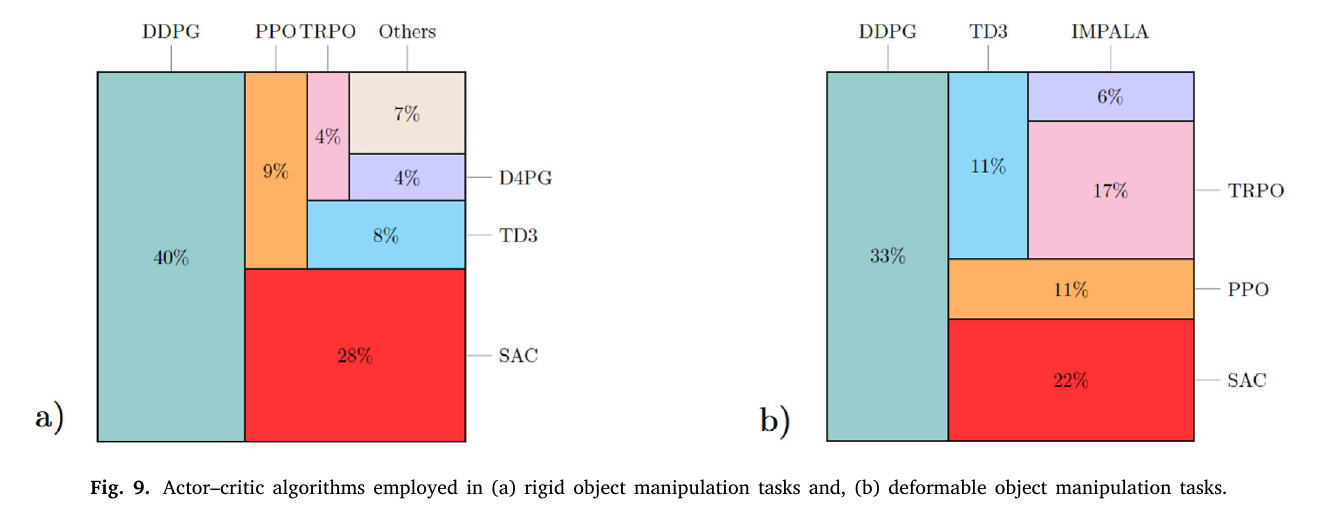
Safety strategies used

Overview of studies in Rigid Object Manipulation