Bi-Weekly Advisor Meeting 27 of November 2025
Context
- Finished RL course
- Use of Neural Networks for feature construction
- Policy Gradient Algorithms
- Actor-Critic Methods
- Gaussian Policies for Continuous Action Spaces
- Search for papers combining HRC & Contact-rich & RL
- No review papers found
- Broadening to non-review articles showed 124 articles under SE
- Should look for HRC & Contact-Rich only, leaving RL out of it, maybe I’ll find a decent review paper this way
- Analysis of Reinforcement Learning Based Variable Impedance Control for High Precision Human-robot Collaboration Tasks
- Setting up containerized Isaac Lab
- Settled on using Distrobox for ease of use and integration with host OS. Discarded Docker as I am not looking for isolation/sandboxing, I just need to use a software compatible with Ubuntu 22.04 (tested in Arch, launched but yielded many errors).
- Set up installation scripts to get all my dev tools, Isaac and Cuda working with one command. This will be useful whenever I need to work on one of the lab’s server. And also for the sake of reproducibility if I ever need to reinstall. Or even if somebody else in the lab wants to try it out.
- Isaac requires Ubuntu 22.04 and Python 3.11. To ensure Python compatibility I used
pyenvwith thepyenv-virtualenvplugin. Up until now I just usedvirtualenvwrapper, but this tool does not allow the creation of virtual environments with different Python versions.
Reinforcement Learning Based Variable Impedance Control for High Precision Human-robot Collaboration Tasks
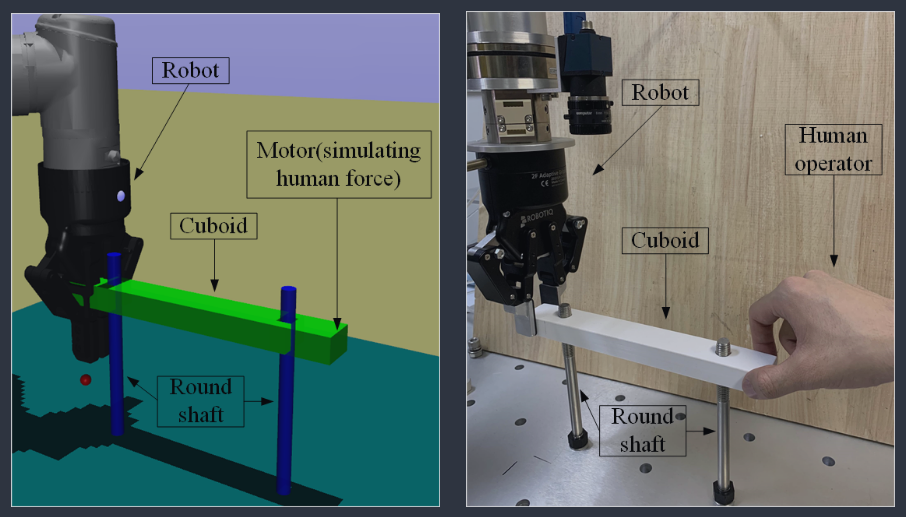
Descriptive Analysis
This paper proposed an impedance control method for high precision collaborative assembly tasks. The case study involved fitting shafts through cuboids with holes. Classic Peg-in-Hole. The shaft-hole clearance was 0.1 mm. The authors experimented both with 1 or 2 holes/shafts. The cuboid initial position was fixed and the shafts’ initial positions varied within a bounded range.
In the first phase, using a depth camera, the robot locates and grabs the cuboid, and then moves along a reference trajectory without the human operator’s intervention. In the second phase, the human operator needs to correct the possible position deviation. During this time, the robot follows the human operator’s intention and senses the human force to change the end effector’s position.
This work used PPO to determine the impedance parameters M, B, K (inertia, damping, and stiffness). After, these parameters were fed to the robots’ controller, which uses the following differential equation to compute the change in position.
\[M_t \Delta \ddot{x} + B_t \Delta \dot{x} + K_t \Delta x = \Delta f\]The reward signal was the sum of the distance between the two end points of the object and the two target points.
In simulation, the human force was replicated by a motor applying a force proportional to the distance from the target position. The authors argued that this approach has similar reasoning in comparison to the forces applied by a human. A human would apply a force proportional to how far off the shaft was from the hole.
The authors reported that due to the limitations of the physics engine in the simulation environment, the cuboid may get stuck due to collision detection. The simulator used was MuJoCo.
Key Takeaways for My Work
While this article presents interesting information, it diverges from my work in a few ways and has some notable gaps:
- I’m not so sure that this work is not a pure contact-rich task per se. It covers pre-contact, which I’m not interested in. It is not so clear through the paper how they get to the change in force used for in the aforementioned equation. I reckon they are just using the net force applied on the end effector. They do not seem to be taking the contact data to make the agent smarter. The human is the master and the robot is the slave, following blindly what the human suggests. The RL agent “simply” learns the impedance parameters so that the approach would still work for many humans applying different forces.
- While they show a physical set-up in the beginning to draw readers in, they later reveal that they did not leave simulation.
- The paper regards more the precision of the collaboration, whereas I would like my research to steer more into allowing a single agent to collaborate in multiple tasks, hence the later objective of implementing Meta RL.
The papers highlight some points that are indeed relevant though:
- Differences in the skills of various operators bring difficulties to collaborative robots. This raises an extremely important question. Should I tailor the agent I will build to be sort of my little metal friend, designed to collaborate efficiently WITH ME, or be designed to collaborate with anyone? I believe both options are valid, and the former is definitely easier to train and has potential for more interesting results, which can be eye-catchy in an article.
- Common collaboration tasks are collaborative assembly and collaborative transportation, with a special emphasis on the latter with heavier objects.