Bi-Weekly Advisor Meeting 18th of December 2025
Context/Summary
On my previous meeting with my advising team, I was reminded that I was leaving on key thematic out of my state-of-the-art review, which will come in later in my work: Meta-Learning. So far I had been looked into:
- Contact-rich relating to Reinforcement Learning (Post);
- Contact-rich Human-Robot Collaboration (Post);
- Intent comprehension through contact interaction (Paper)
From here I was missing Meta-Learning and Model-Based Reinforcement Learning.
Regarding the latter, I have not read articles focused solely on Model-Based RL with Contact-rich HRC. I have however stumbled across a few paragraphs in other papers discussing Human-Modelling, which will be something I will be elaborating further down in this post. Come to think of it, the human is the most complex and hard entity to model in the environments I am interested in.
Regarding the former, these weeks have been a bumpy ride. TLDR is that I’m feeling big gaps in Meta-Learning theory to properly understand what I am reading. After tweaking the keywords, I settled on the following search equation:
TITLE-ABS-KEY ( "human-robot interaction" OR "human robot interaction" OR "human-robot collaborat*" OR "human-robot cooperat*" OR "physical human-robot interaction" OR "phri" OR "collaborative robot*" OR "cobot*" OR "hrc" )
AND TITLE-ABS-KEY ( "meta RL" OR "meta-RL" OR "meta reinforce*" OR "meta-reinforce*" OR "meta learning" OR "meta-learning" OR "metalearning" OR "meta-learn*" )
… that yielded 30 articles, from which I saved 12 with interesting titles: (bold means thoroughly analised)
- Adaptable automation with modular deep reinforcement learning and policy transfer
- Complementary learning-team machines to enlighten and exploit human expertise
- Active Exploration and Parameterized Reinforcement Learning Applied to a Simulated Human-Robot Interaction Task
- A behavioural transformer for effective collaboration between a robot and a non-stationary human
- Meta-Learning-Based Optimal Control for Soft Robotic Manipulators to Interact with Unknown Environments
- Fast Adaptation with Meta-Reinforcement Learning for Trust Modelling in Human-Robot Interaction
- Meta-Learning for Text-Based Object Localization in Robotic Manipulation with DNN and CLIP
- Concept of an Intuitive Human-Robot-Collaboration via Motion Tracking and Augmented Reality
- Fast User Adaptation for Human Motion Prediction in Physical Human–Robot Interaction
- Developing the robotic space-force boundary of physical interaction perception in an infant way
Considering there are not review papers on this matter yet, I plan to do a short review of these papers in this post, highlighting the details they share, and also where I struggled more.
Generally, I found myself a bit lost reading these papers. I feel like I still lack key foundations in Meta-Learning to properly grasp what I am reading. Given this, I have been considering to diverge my attention for a short period of time to read at least the few chapters of A Tutorial on Meta-Reinforcement Learning (DOI 10.1561/2200000080). This tutorial was published earlier in April of this year, on Foundations and Trends in Machine Learning. It is co-authored by Chelsea Finn, one of the biggest names in Meta-Learning. Simultaneously, I’m hesitant about possibly investing time into something that I will work with only much later on. It is easy to fall in the rabbit hole, so if I choose this path I have to thread carefully to only gather the key aspects to help me understand the papers I am trying to review for the review paper I plan to publish next year.
On an unrelated note, I found a post about a very interesting SAC tutorial using SB3 and PyTorch while browsing through Reddit on r/reinforcementlearning. I am planning on following this soon, I reckon I will sort of kill 2 birds with 1 stone, as I have been meaning to start learning SB3 for my future endeavors as well as SAC, one of the leading algorithms in Reinforcement Learning SoTA. On the previous meeting, we talked about Isaac Lab, a very powerful RL simulator for robotics from NVIDIA. Since then, I left the learning of this simulator on hold. I feel like I benefit more from learning SB3 and such right now, as I can not do much more other than create simulation environments without knowing these tools first.
Short Critical Review
I was initially thinking about doing a meta analysis of the papers read, but I did not gather enough quantitative data to do so. Given this, I will do more of a simple critical review, narrating the key themes and insights. I only analyzed the abstracts, introductions, related works and conclusions. Details about the methods in the individual studies are not important right now. For now, I’m content to find general trends and topics that pop up frequently in Meta-Learning studies.
A behavioural transformer for effective collaboration between a robot and a non-stationary human
This paper discusses a topic with which I was previously unfamiliar, but which is highly relevant: Human Modeling
In human-robot collaboration scenarios, the human is typically considered part of the environment. This makes the environment time-dependent, due to the non-stationary human behavior. The human can not be an agent because the robot has no direct control over its actions. If an environment is non-stationary it means that either or both the state transition function and the reward function vary over time.
One frequent approach to deal with non-stationary environments is the use of Multiagent RL. Multiagent RL: Multiagent reinforcement learning (MARL) aims to tackle non-stationarity. This approach is not feasible for human-robot collaboration settings as it is not possible to control the human agents.
Side Note on how MARL tackles non-stationarity Click to expand
Answer from GPT, modified.
In standard (single-agent) reinforcement learning, the environment is usually assumed to be stationary: the transition dynamics and reward function do not change over time. This assumption is violated as soon as multiple learning agents are present.
Why non-stationarity arises
In a multi-agent setting, each agent is part of the environment from the perspective of the others. As agents learn and update their policies, their behavior changes over time. Consequently:
- The transition dynamics experienced by any given agent change.
- The reward distribution may also change.
- From a single agent’s viewpoint, the environment is no longer stationary or Markovian. The Markovian property of an environment is the core idea that the future depends only on the present, not the past; the next state and reward are conditionally independent of all previous states and actions, given only the current state and action.
This phenomenon is known as environmental non-stationarity.
Why MARL “aims to tackle” non-stationarity
Multiagent reinforcement learning explicitly acknowledges and addresses this issue by designing methods that can cope with or mitigate non-stationarity, for example:
- Centralized training, decentralized execution (CTDE):
During training, agents have access to joint observations or joint actions, making the learning problem closer to a stationary one. - Opponent / agent modeling:
Agents learn representations or models of other agents’ behaviors, allowing them to adapt to policy changes. - Joint policy learning:
Learning coordinated policies reduces uncontrolled policy drift. - Game-theoretic formulations:
Equilibrium concepts (e.g., Nash equilibria) provide stable solution targets despite learning dynamics.
Key intuition (one-sentence takeaway)
MARL aims to tackle non-stationarity because, in multi-agent environments, each agent’s learning continuously changes the environment experienced by others, violating the stationarity assumptions of standard RL.Given that MARL is not an option, this study also discusses some ways to model human behavior, among which:
- Programming rules (the article did not give examples about this)
- Imitation learning
- Probabilistic models with or without Boltzmann rationality (agent is boundedly rational: it tends to prefer higher-value actions, but it may still choose lower-value ones with some probability.)
From this citations in article I also saved some potentially interesting articles on human modelling for AI applications:
- LESS is More: Rethinking Probabilistic Models of Human Behavior (78 citations);
- Optimal Behavior Prior: Data-Efficient Human Models for Improved Human-AI Collaboration (17 citations);
- Prediction of Human Behavior in Human–Robot Interaction Using Psychological Scales for Anxiety and Negative Attitudes Toward Robots (588 citations)
The article uses follows the zero-shot Meta-Learning paradigm. On the Meta-Learning tutorial aforementioned, there are chapters for both zero-shot and multi-shot Meta-Learning. As a general AI concept, I have the vague idea that a zero-shot approach is one where a model can understand a new sample never seen during training, relying on pre-learned semantic knowledge. This concept seems to overlap with the definition of Meta-Learning, but that is where my understanding ends. The search equation I mentioned in this article shows a review article about few-shot learning methods, but I failed to recognize before how it could relate to what I am studying. Might be worth a read.
Like in other articles, a frequent environment used to test human models is the soccer pass. The agent has to learn the human pass behavior, more or less power, varying angles, etc.
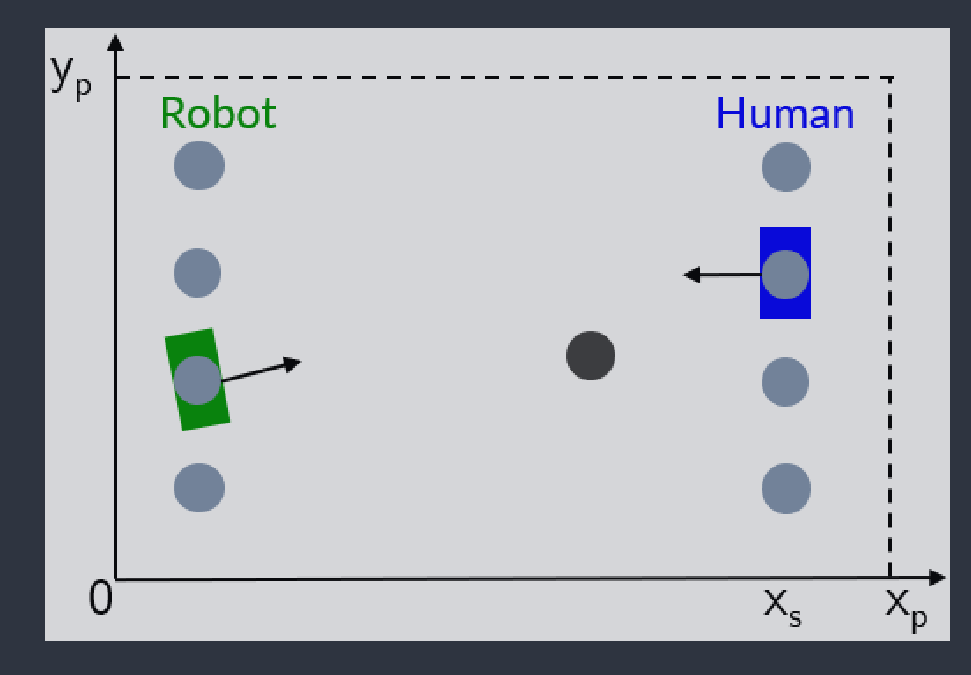
Active exploration and parameterized reinforcement learning applied to a simulated human-robot interaction task
This study was too overly focused on multi-armed bandits. Multi-armed bandits are a typical type of problem used when one is first learning Reinforcement Learning. Whereas typical RL environments are modelled with a Markov Decision Process (MDP), involving state transition probability functions, discount factors, etc… bandits are a simpler environment with only one state. For example choosing a restaurant to eat for a series of days. The concern is shifted from which action on a certain state to only which action has a higher value.
Like the previous study, this one also refers Boltzmann Rationality for modelling human actions as well as the 2D Soccer Pass environment. Although the latter only briefly.
Adaptable automation with modular deep reinforcement learning and policy transfer
This study talks about a lot of new (to me) ideas in modular Reinforcement Learning. In its core, Modular RL is the idea of decomposing a task into several simpler modules, which can be learned separately and reused in learning new manipulation tasks. Each module can have its own reward function.
The general idea is built on the assumption that modules are reusable neural network functions. Therefore, they can be pre-trained and recombined in different ways to tackle new tasks. Thus, instead of training a single network on a complex task that would take a long time, one can train on many different task module networks.
The paper proposes a new variation of the SAC algorithm, HASAC. Its goal is to enhance an agent’s adaptability to new tasks by transferring the learned policies of former tasks to the new task through a “hyper-actor”. I did not dive deeply into how this works, as I have still to properly study the baseline SAC algorithm.
Uses the Meta World benchmark, from 2020, containing various single and multi-tasks robotic manipulation tasks.
The study also highlights one concept that has a particular interest in Meta-Learning, inductive bias.
From here:
Inductive bias is restricting your hypothesis space to a certain class of hypotheses. In simpler terms, it’s a guess about what the function looks like, before looking at data. Take regression: if you have a finite set of points, you can draw infinitely many different functions that fit them. But if you assume that the function is linear, you remove almost all possibilities (there are still infinitely many linear functions, but way, way fewer than functions in general). Common inductive biases are smoothness and sparsity. Pretty much all used models include smoothness somehow: similar inputs have similar outputs. Sparsity is also very common: it’s the assumption that the function depends on few inputs. Without an inductive bias, machine learning is impossible. If something in machine learning works well, more often than not it’s because of its inductive bias. For example, convolutional neural networks are biased towards the kind of structure present in images: pixels next to each other are similar, there are similar features (e.g. eyes) present in different locations, big features are made of smaller features. A consequence of this is the no-free-lunch theorem. If your inductive bias works well on some type of data, it has to work badly on other kinds of data.
I think this takes special importance in Meta-Learning because the assumptions we make about the tasks we are learning can influence what we expect new tasks to look like. This may or may not be ideal. I would guess it depends if we know which tasks the agent might be faced with.